Web
neuere Einträge ...RDFa à la twoday, Teil III: Finale
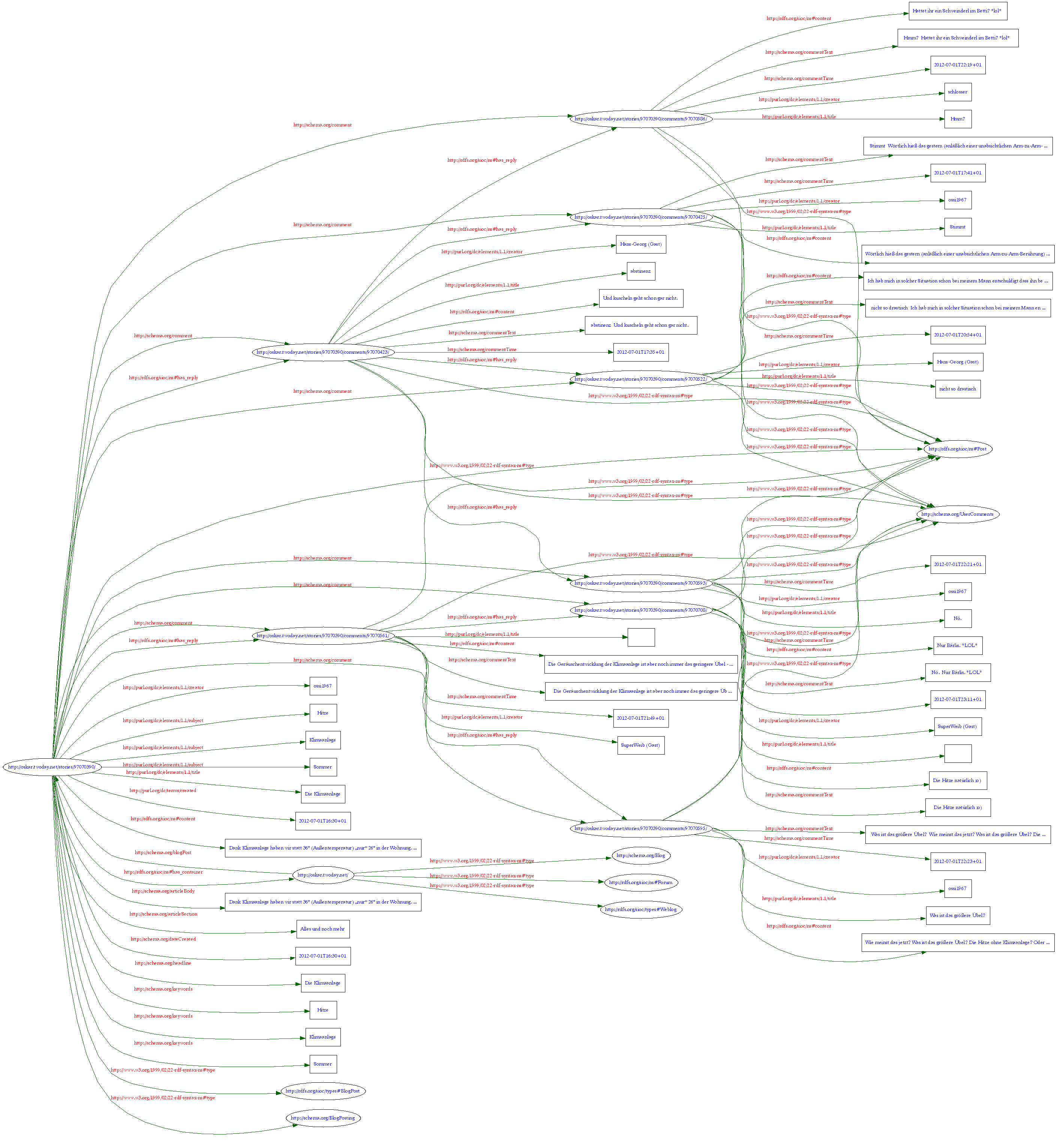
 Nach mehreren Anläufen (siehe hier und hier) und einem über Jahre gequälten Testblog ist es nun soweit: Dieses Blog ist mit RDFa-Markup angereichert. Mit RDFa kann ich standardisierte, computerlesbare Zusatzinformationen in die Seite einfügen. Leider verhindert twoday.net, daß ich das volle Potential der Technologie ausschöpfe (dazu mehr später), aber zumindest ein paar Basics zur Seitenstruktur konnte ich umsetzen. Eine Suchmaschine erkennt nun besser, was der eigentliche Artikel ist, wo die Kommentare anfangen, ob ein Datum einfach nur zufällig auf der Seite steht oder die Erstellungszeit eines Kommentars bezeichnet und so weiter. Wie das konkret aussieht, zeigt Google. Dieser Artikel wird von der Maschine so verstanden. (Die grafische Darstellung ist hier zu finden.)
Nach mehreren Anläufen (siehe hier und hier) und einem über Jahre gequälten Testblog ist es nun soweit: Dieses Blog ist mit RDFa-Markup angereichert. Mit RDFa kann ich standardisierte, computerlesbare Zusatzinformationen in die Seite einfügen. Leider verhindert twoday.net, daß ich das volle Potential der Technologie ausschöpfe (dazu mehr später), aber zumindest ein paar Basics zur Seitenstruktur konnte ich umsetzen. Eine Suchmaschine erkennt nun besser, was der eigentliche Artikel ist, wo die Kommentare anfangen, ob ein Datum einfach nur zufällig auf der Seite steht oder die Erstellungszeit eines Kommentars bezeichnet und so weiter. Wie das konkret aussieht, zeigt Google. Dieser Artikel wird von der Maschine so verstanden. (Die grafische Darstellung ist hier zu finden.)
Erfahrungen? Grundsätzlich positiv. Ich habe RDFa 1.1 verwendet und bin so den Fallstricken aus dem Weg gegangen, über die man stolpert, wenn man den Server nicht selbst kontrollieren und deshalb kein echtes XHTML ausliefern kann. In einigen Fällen hätte ich mir die elegante Namensraum-Systematik von XHTML und RDFa 1.0 zurück gewünscht, aber das ist wohl nur Geschmackssache.
Ein bißchen übel war, daß ich ständig auf das Vokabular aus schema.org Rücksicht nehmen mußte. Man kann darauf nicht verzichten, weil die großen Suchmaschinen dieses Vokabular bevorzugt verwenden. Andererseits ist schema.org teilweise extrem mühsam und umständlich. Es dupliziert längst vorhandene Funktionen aus anderen Vokabularen, tut dies dann aber nur halbherzig oder kompliziert … Man merkt einfach, daß hier oberflächlich zusammengeschustert wurde, während etablierte Standards wie Dublin Core oder SIOC durch jahrelangen Input aus der Community ausgereift sind. Beispiel: Das Beschreiben von Kommentaren und Antworten auf Kommentare ist in schema.org de facto unmöglich. In SIOC? Ein Kinderspiel. Oder: Das Hervorheben des Autors, wenn man nicht gleich den ganzen Namen verraten, sondern sich auf ein Pseudonym beschränken will (wie hier üblich). Im RDF-Universum leicht über Dublin Core abzuhandeln, mit schema.org ein Eiertanz.
Mein Kompromiß: Ich verwende mehrere Vokabulare parallel. Mag sein, daß Google und Yahoo! keine Informationen aus SIOC, FOAF oder Dublin Core auswerten wollen, aber vielleicht tuts ja jemand anderer. Wo es ging, hab ich auch schema.org verwendet.
Die große Enttäuschung kommt nicht aus RDFa, sondern von unserem twoday.net-Server. Ich kann hier nämlich appetitliches RDFa in die fixen Abschnitte rund um die Blog-Postings und Kommentare herum einbauen. Ich kann RDFa aber nicht im Blog-Posting selbst verwenden. Das reduziert die Nützlichkeit dann doch. Die fixen twoday-Vorlagen wissen ja nichts über den Inhalt des Artikels. Sie wissen, was Überschrift, was Artikel, was Kommentar ist. Sie wissen, wo das Erstellungsdatum steht, in welche Unterkategorie der Artikel gehört, wer ihn geschrieben hat. Diese Informationen kann ich also in RDFa übersetzen. Genau das habe ich getan, genau das kann Google jetzt verwenden. Was nicht geht ist, den Inhalt selbst aufzufetten. RDFa würde mir erlauben, bei Rezepten genau anzugeben: Was ist eine Zutat, welches Foto stellt das fertige Gericht dar, welcher Teil des Textes bezeichnet die Zubereitungszeit, … Oder bei Ereignissen wie meinem Geburtstag oder einem Konzert: Was genau ist es, wo findet es statt, wann beginnts, wie lange dauert es, … Oder auch nur beim Foto neben dem Blog-Artikel anzugeben, wen es abbildet. Nichts davon kann twoday.net. Ich kann den entsprechenden Code beim Erstellen des Artikels zwar eingeben, beim Löschen aber fliegt er raus, weil der Server ihn nicht für gültiges HTML hält. Schade.
Immerhin: der Anfang ist gemacht. Wir sind Semantic Web! :)
noch kein Kommentar - Kommentar verfassen
My URI = My WebID
Seit einigen Tagen habe ich auch eine WebID, die mich fürs Login auf neuen Seiten eindeutig identifiziert.
Seit vorgestern sind die beiden Dinge eins. Beides ist ja schließlich drauf aus, mich zu identifizieren. Beides beschreibt mich mittels RDF, noch dazu weitgehend mit dem gleichen Vokabular. Wozu also zwei Öltanks sein? Schwupps hab ich die WebID-spezifischen Teile (also vor allem die Zertifikats-Informationen) in die Daten über http://www.welzl.info/id/oskar.welzl eingebaut … Pfeift schon!
Ganz nebenbei gabs (neben inhaltlichen Updates) noch die Umsetzung eines genialen Vorschlags, den Daniel E. Renfer (aka duck1123) auf meinem µBlog gepostet hat:
http://www.welzl.info/id/oskar.welzl existiert ja nicht als Dokument - klar, weil Die URI mich bezeichnet und nicht eine Datei im Web. Der Server schickt stattdessen http://www.welzl.info/id/o.w mit Informationen über http://www.welzl.info/id/oskar.welzl zurück, und zwar je nach Client-Anforderung entweder als maschinenlesbare RDF/XML-Datei oder als für Menschen verdaubare HMTL-Seite. Daniel hat nun vorgeschlagen, auch die HTML-Version mit RDFa anzureichern und somit maschinenlesbar zu machen. Hab ich gleich eingebaut - funktioniert perfekt!
Ich liebe es, wenn sich am Schluß alles so einfach zusammenfügt. Ich bin einfach immer http://www.welzl.info/id/oskar.welzl. Egal ob jemand Informationen über mich veröffentlicht oder ob ich selbst mich mittels WebID irgendwo einlogge. Die Bezeichnung ist immer http://www.welzl.info/id/oskar.welzl. So einfach muß es sein.
noch kein Kommentar - Kommentar verfassen
WebID: Coole Technik fürs einheitliche Login
Es gibt verschiedenste Versuche, diese unnötigen Eingaben überflüssig zu machen. Die dümmste und gefährlichste Variante ist, sich mit existierenden Facebook- oder Google-Accounts auf fremden Seiten einzuloggen. Viel besser, weitgehend etabliert und ausreichend offen dagegen ist OpenID. Dabei handelt es sich um ein dezentral angelegtes Protokoll. Ich kann mir einen beliebigen OpenID-Provider aussuchen, mich dort registrieren und von da an auf jeder OpenID-kompatiblen Seite mit immer den gleichen Daten einloggen, ohne mich dort nochmal extra registrieren zu müssen. Das ist die Technik, die ich selbst derzeit am häufigsten verwende.
Gerade entdecke ich eine weitere Alternative, an der zwar noch gebastelt wird, die aber aus meiner Sicht sehr spannend wirkt: WebID. Das System funktioniert auf Basis etablierter Standards wie TLS, X.509-Zertifikaten und RDF. Im Prinzip liegt die ganze Standard-Information über mich in einem RDF-Dokument, das das FOAF-Vokabular benutzt. Zusätzlich enthält dieses Dokument den öffentlichen Schlüssel eines Zertifikats, das ich in meinem Browser abgelegt habe. Wenn ich mich nun erstmals auf einer mir bisher unbekannten Seite einlogge, verlangt die von mir ein Zertifikat (das ich über ein Drop-Down im Browser auswähle). Im Zertifikat hinterlegt ist die Adresse des WebID-Dokuments, das meinen Namen, mein Foto und andere Informationen enthalten kann. Paßt der öffentliche Schlüssel im WebID-Dokument zu dem Zertifikat, mit dem sich mein Browser gerade identifiziert hat, dann wird mein Login akzeptiert und ich habe ohne jeden Aufwand ein neues Profil angelegt.
Natürlich geht niemand davon aus, daß Leute (so wie ich gestern) ein Zertifikat auf der Kommandozeile erstellen und das dazugehörige RDF-Dokument per Hand editieren und hochladen. Der Normalfall wird sein, daß ein Webservice, das WebID unterstützt, Zertifikatsgenerierung und Anlegen eines WebID-Dokuments für bestehende User automatisiert. Daß ich aber auch meine eigene, handgestrickte WebID verwenden kann, ist eine durchaus feine Sache: Ich mag Technologien, die ich auch ganz auf mich allein gestellt und unabhängig von irgendeinem Drittanbieter nutzen kann. WebID scheint so etwas zu sein. Simpel und effizient. (Einziger Nachteil, wie bei allem, was auf Verschlüsselung beruht: Irgendwie muß man einen Weg finden, das WebID-Zertifikat bei sich zu tragen. Sonst klappts nicht mit dem Login im Internet-Café.)
Tips zum Ausprobieren: Dieses Script hilft beim Erstellen eines Zertifikats mit OpenSSL; MyProfile ist ein experimentelles Service, bei dem man sich mit WebID einloggen kann.
Google schließt mein Konto: Pornographie
Heute bekomme ich Post vom amerikanischen Bruder: Dieses Blog verstößt wegen seiner pornographischen Ausrichtung gegen die Benutzungsrichtlinien. Ich habe drei Tage Zeit, die problematischen Textstellen zu löschen. Ansonsten wird mein Google-Account gesperrt. Eine Antwort auf die Mail ist nicht möglich.
Liebe Kinder drüben überm großen Teich, ich schreibt Euch hier jetzt mal was wirklich Pornographisches rein: Ihr könnt Euch mit ████████ ██████████ die ███ █████████, bis ████████████ ████ █████████ mit Nägeln ██████████ ████ hat. ;)
Allen anderen Lesern: Schämt Euch! Schämt Euch dafür, daß Ihr Euch jahrelang an meinen perversen Texten hier aufgegeilt habt!
RDFa à la twoday, Teil II
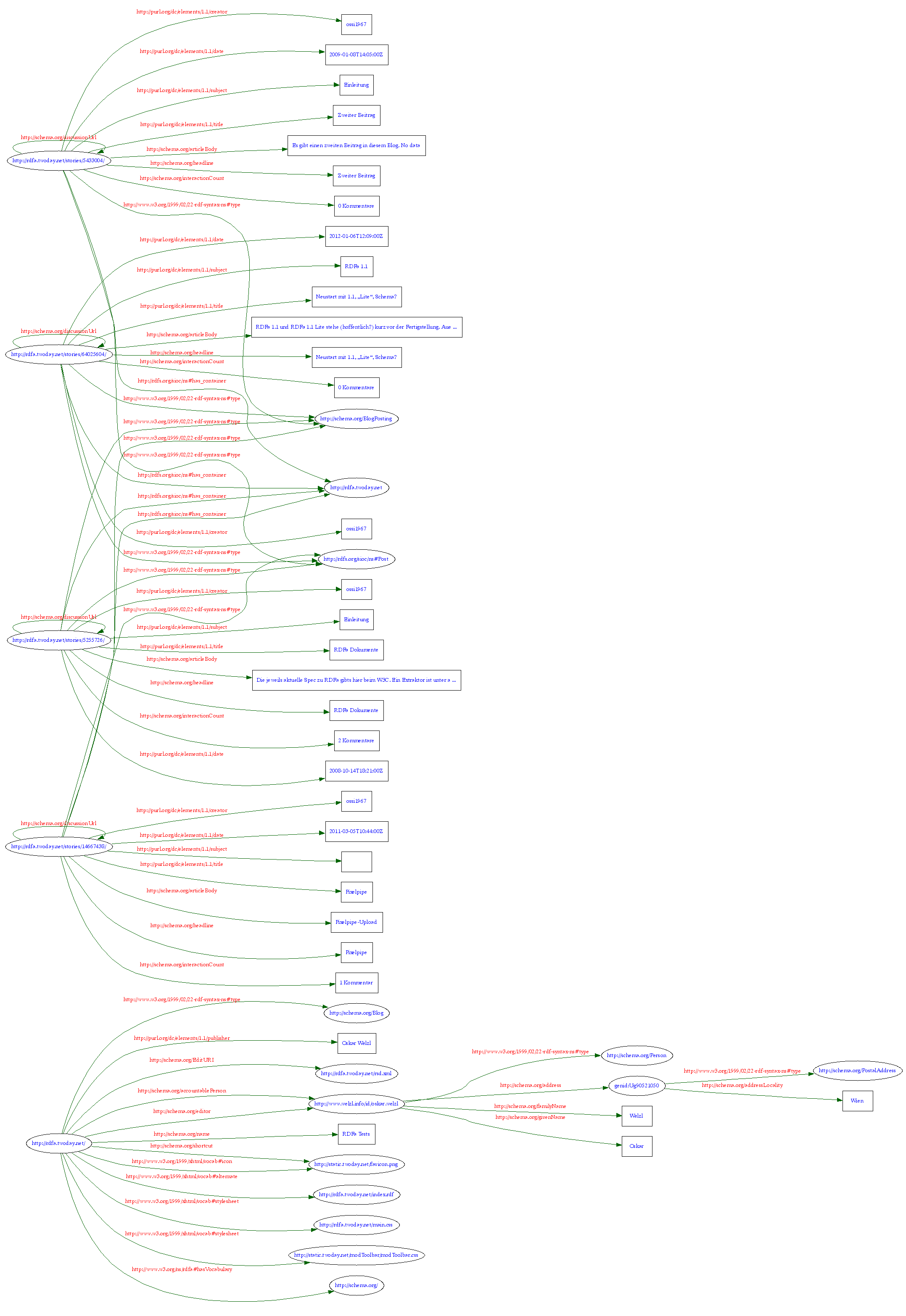
2008 habe ich zum ersten Mal versucht, maschinenlesbare Zusatzinformationen nach der (damaligen) RDFa-Spezifikation in ein twoday.net-Blog einzubauen - und bin kläglich gescheitert. In den letzten Monaten hat sich aber einiges getan: RDFa 1.1 wird sich, das ist abzusehen, wesentlich von der 2008 gültigen Version 1.0 unterscheiden und dadurch technische Probleme aus dem Weg räumen. Außerdem gibt es neue Antworten auf die Frage nach dem „Warum?“. Wo also stehen wir 2012? Und was könnte ich für mein Blog hier verwenden?
Ich habs im RDFa-Testblog von 2008 ausprobiert. Was eine Maschine daraus lesen kann, wird in diesem Diagramm sichtbar. Ziemlich beeindruckend, finde ich. Aber sehen wir mal im Detail, was für mich neu war:
Vorweg: Alle folgenden Aussagen zum „neuen“ RDFa beziehen sich auf eine Version 1.1, die noch nicht als offizielle W3C-Empfehlung vorliegt. Noch wird daran gefeilt - sehr heftig sogar. Ich gehe aber davon aus, daß der Editor’s Draft vom 15.12.2011 dem Ergebnis sehr nahe kommen wird … sofern es überhaupt ein Ergebnis gibt, doch dazu später.
- RDFa verläßt sich nicht mehr auf den XML-spezifischen Mechanismus der Namensraum-Deklaration, um ein Vokabular einzuführen. Das ist zwar deutlich weniger elegant, ermöglicht aber die Nutzung in Dokumenten, die kein XML sind - wie z.B. in twoday.net-Blogs. Heißt: Ich konnte im Testblog RDFa einbauen ohne mich darum zu kümmern, ob die ganze Tagsoup drumherum irgendeinem (X)HTML-Standard entspricht. Tatsächlich habe ich das Ergebnis von neuen RDFa-Parsern lesen lassen, es funktioniert.
- Die Autoren von RDFa haben unter dem Namen „RDFa Lite“ ein Subset definiert, das in seiner Funktionalität sehr stark an das von der Industrie bevorzugte Microdata-Modell erinnert. Microdata ist simpler, aber zentralistischer, weniger leistungsfähig und vor allem weniger flexibel als RDFa. Wahrscheinlich wird es aber für RDFa wichtig werden, eine Microdata-ähnliche, allgemein anerkannte Mindestvariante anbieten zu können. Im Testblog habe ich einfach versucht, möglichst konform zu RDFa Lite zu bleiben (und somit implizit auch „in Microdata zu denken“). Das ist mühsam und umständlich, wenn man RDF gewöhnt ist. Außerdem schränkt es die Möglichkeiten doch sehr ein: Die Einfachheit kommt nicht ohne Preis, manches läßt sich in „Lite“ einfach nicht mehr ausdrücken.
- Im Juni 2011 mußten die um ein semantisches Web bemühten Personen und Organisationen zunächst einen herben Rückschlag einstecken: Mit schema.org haben Google und andere Suchmaschinenbetreiber das Rad neu erfunden und ein auf Microdata basierendes Vokabular vorgestellt, das alle bestehenden völlig ignoriert. Ein Licht am Horizont gibt es erst wieder seit November: RDFa Lite soll von den Suchmaschinenbetreibern gleichberechtigt mit Microdata als Syntax anerkannt werden - solange das schema.org-Vokabular verwendet wird. In der Praxis könnte das bedeuten: Eine Website verwendet volles RDFa 1.1 (also nicht nur die lite-Version) mit etablierten Vokabularen (SIOC, Dublin Core, FOAF, …) und den Ausdrücken aus schema.org. Die großen Suchmaschinen lesen nur, was als RDFa Lite gültig ist und schema.org-Vokabeln enthält, während alle zusätzlichen Informationen für fortgeschrittene RDF-Anwendungen unverändert erhalten bleiben. Ob Google tatsächlich schon RDFa 1.1 Daten aus meinem Testblog liest, bezweifle ich erst mal. Wahrscheinlich warten die, bis die Spezifikation engültig fest steht.
Apropos bis die Spezifikation engültig fest steht
: Spannend wird, wie sich das W3C aus der Sache mit den konkurrierenden Standards RDFa und Microdata herauswindet. Es gibt Bestrebungen, die Veröffentlichung beider Spezifikationen zu unterbinden und darauf zu warten, daß die beiden Gruppen sich einigen. Andererseits wäre es nicht das erste Mal, daß zwei Standards parallel existieren, die mehr oder weniger dem gleichen Zweck dienen.
Wenn sich die Geschichte wiederholt, wird der schlechtere Ansatz (Microdata) sich gegen den überlegenen (RDFa) durchsetzen … so wie sich „HTML“ 5 durch die Macht der Konzerne gegen das wesentlich brilliantere XHTML 2 durchsetzen konnte. Noch ist aber nicht alles verloren. Der Kunstgriff mit „RDFa Lite“ könnte noch einiges ändern. Mal sehen.
Einen guten Überblick über den aktuellen Status von RDFa bietet Ivan Herman im Artikel Where we are with RDFa 1.1?. Eine Gegenüberstellung von RDFa, Microdata und den etwas in Vergessenheit geratenen Microformats hat Manu Sporny unter dem Titel An Uber-comparison of RDFa, Microdata and Microformats veröffentlicht.
noch kein Kommentar - Kommentar verfassen
Besuch vom N9
Mozilla/5.0 (MeeGo; NokiaN9) AppleWebKit/534.13 (KHTML, like Gecko) NokiaBrowser/8.5.0 Mobile Safari/534.13
Wie aufregend! :)
2 Kommentare - Kommentar verfassen
SPARQLing foaf:Images
Geil. Seit einigen Jahren schon gibt es ja eine maschinenlesbare Kopie dieses Blogs im RDF-Format. (Siehe diesen Beitrag von 2007.) Dieser Blog-Abzug wird von einigen wenigen Zeilen statischer Zusatzinformationen angereichert und ergibt in Summe einen Datenbestand, ders durchaus in sich hat: Über die Verknüpfung völlig unabhängiger Datenquellen ist es möglich, zu fast allem hier Zusatzinfos zu erhalten. Zu den Themen der Beiträge Infos aus Wikipedia, zu den Autoren der Kommentare Fotos und Namen, zu mir selbst ein Persönlichkeitsprofil und meine Sprachkenntnisse … Genug jedenfalls, daß man es nicht im öffentlichen Netz haben und von Google indizieren lassen will.
Genauer müßte man eigentlich formulieren: „Über die Verknüpfung völlig unabhängiger Datenquellen wäre es theoretisch möglich, zu fast allem hier Zusatzinfos zu erhalten.“ So richtig praktische, schlaue Abfragetools hab ich mir bisher noch nicht angesehen. Irgendwie hats mich gestern und heute aber in den Fingern gejuckt. Ich wollte etwas mit dieser Datenflut auf meiner Festplatte anstellen.
Um RDF vernünftig auszuwerten, braucht man SPARQL. SPARQL ist eine SQL-ähnliche Abfragesprache, die eben nicht Tabellen, sondern Triple-Stores auswertet. Klang für mich immer sehr trocken und mühsam, kam vor allem ohne spitze Klammern aus, also hab ichs bleiben lassen. Bis jetzt. Gestern angeschaut, heute damit gearbeitet und - voilà! - schon hab ich eine Übersicht aller Fotos aus diesem Blog (und manchen anderen Quellen), geordnet nach dem Namen der abgebildeten Personen. Edel. Eine wunderbare HTML-Seite, auf der jeweils ein Name als Überschrift steht, dann alle Fotos, auf denen die jeweilige Person zu sehen ist, dann der nächste Name usw. usw.
Es tut mir in der Seele weh, daß ich das Dokument nicht einfach hochladen und herzeigen kann. Ist mir dann aber doch zu sensibel: Immerhin stehen fast alle Abgebildeten mit ihren vollständigen Namen drin, dazu auch gleich die Fotos aus acht Jahren Blog-Geschichte … Das mag wohl nicht jeder öffentlich zur Schau gestellt haben. (Was ein Dilemma des Semantic Web offenbart: Die fraglichen Fotos sind ja schon alle öffentlich im Web, die meisten davon sogar hier auf diesem Blog. Wer mich kennt, erkennt mich auf jedem dieser Fotos. Trotzdem ist die systematische Abfrage „Zeige mir alle Fotos, auf denen Oskar Welzl abgebildet ist“, vom Standpunkt der Privatsphäre her bedrohlicher.)
Beeindruckend dabei wieder einmal das nahtlose Ineinandergreifen verschiedenster W3C-Technologien. Die SPARQL-Abfrage ist ja nur die halbe Miete und liefert ein unansehnliches XML-Dokument zurück. Um daraus eine hübsche HTML-Seite zu machen, brauchts XSL(T). Schade, daß sich das W3C mit „HTML“ 5 von dieser genialen Systematik verabschiedet hat und zur völlig unsinnigen Tagsoup-Zeit zurück kehrt.
Apropos HTML: Noch etwas mußte ich unbedingt ausprobieren. In einem zweiten Pseudo-Blog hatte ich bereits vor längerer Zeit RDFa-Metadaten in den HTML-Quellcode eingefügt. Überraschenderweise kann ich die SPARQL-Abfrage auch direkt gegen diese mit RDFa angereicherte Website richten, nicht nur gegen den reinen RDF/XML-Abzug (den ich ja manuell erstellen muß hier). Absolut geiler Stoff. Was mich davon abhält, die RDFa Metadaten auch hier reinzupacken? Die noch fehlende endgültige Spezifizierung von RDFa 1.1 unter anderem, vor allem aber, wieder einmal, der Datenschutz. Es ist wirklich unglaublich, wie mittels RDF aus den unterschiedlichsten Datenquellen umfassendste Informationen zusammengestellt werden können. Die Herausforderung wird sein, nützliche Daten zu finden, die dennoch auch in Kombination mit Fremddaten keine personenbezogenen Details offen legen.
2 Kommentare - Kommentar verfassen
Trassenheide in s/w: 1965
 Wenn man das Ende eines Urlaubs so gar nicht ertragen kann, kommt man auf seltsame Ideen … z.B. die, den Namen des Urlaubsortes auf YouTube zu suchen. Ist das witzig! Ein 8mm-Film, schwarz/weiß wie Gott ihn schuf, über einen Urlaub in Trassenheide im Jahr 1965!
Wenn man das Ende eines Urlaubs so gar nicht ertragen kann, kommt man auf seltsame Ideen … z.B. die, den Namen des Urlaubsortes auf YouTube zu suchen. Ist das witzig! Ein 8mm-Film, schwarz/weiß wie Gott ihn schuf, über einen Urlaub in Trassenheide im Jahr 1965!
Guckst Du hier! Unbedingt!
noch kein Kommentar - Kommentar verfassen
Meine Voting-Sheets in Schleswig-Holstein
 Tja. So ist es. Da les ich die ESC-Artikel in den Blogs von Leuten, die ich persönlich so überhaupt nicht kenn … und was seh ich? Käseigel und meine eigenen Voting-Sheets! ;) *stolzbin*
Tja. So ist es. Da les ich die ESC-Artikel in den Blogs von Leuten, die ich persönlich so überhaupt nicht kenn … und was seh ich? Käseigel und meine eigenen Voting-Sheets! ;) *stolzbin*
Tja, das ist halt nicht nur das Wunder der Eurovision, sondern auch das Wunder des Internets. Ich machs, er druckts, ich sehs … schon irgendwie spooky auch. In ein paar Jahren werd ich noch per TCP/IP den Käseigel plündern können über irgendeine „App“ - vorausgesetzt, ich bekomm das Passwort für die Privatparty. ;)
9 Kommentare - Kommentar verfassen
ESC Radio Dot Com
ESC Radio stellt einen Livestream mit hits of Eurovision, ESC classics and rarities
zur Verfügung, der sich auf jedem x-beliebigen Endgerät abspielen läßt. Zusätzlich gibts (derzeit) Interviews mit den Teilnehmern des heurigen ESC in Düsseldorf.
Anhören! ;)
1 Kommentar - Kommentar verfassen






{kind=link}
{kind=link}