RDFa à la twoday, Teil III: Finale
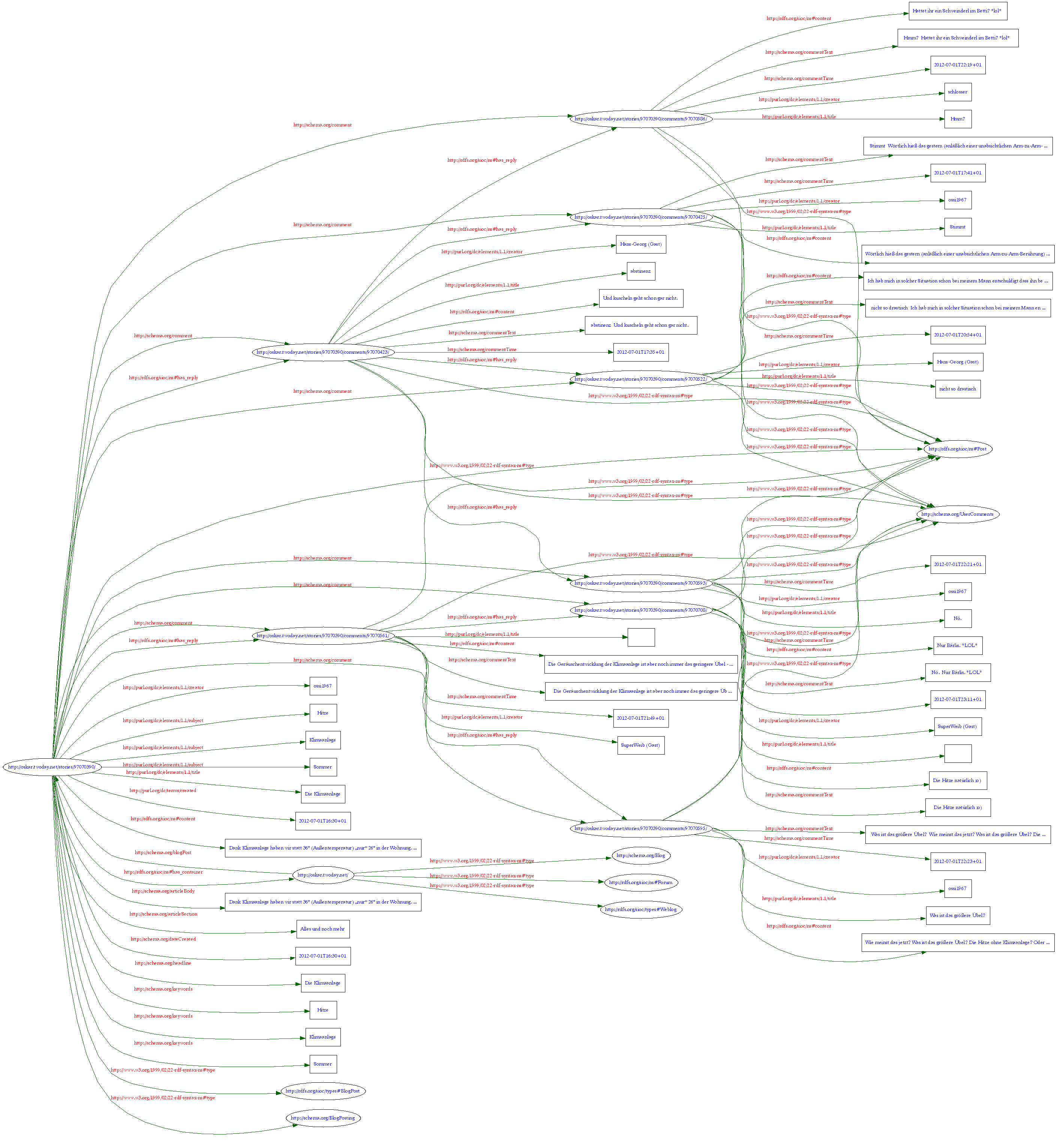
 Nach mehreren Anläufen (siehe hier und hier) und einem über Jahre gequälten Testblog ist es nun soweit: Dieses Blog ist mit RDFa-Markup angereichert. Mit RDFa kann ich standardisierte, computerlesbare Zusatzinformationen in die Seite einfügen. Leider verhindert twoday.net, daß ich das volle Potential der Technologie ausschöpfe (dazu mehr später), aber zumindest ein paar Basics zur Seitenstruktur konnte ich umsetzen. Eine Suchmaschine erkennt nun besser, was der eigentliche Artikel ist, wo die Kommentare anfangen, ob ein Datum einfach nur zufällig auf der Seite steht oder die Erstellungszeit eines Kommentars bezeichnet und so weiter. Wie das konkret aussieht, zeigt Google. Dieser Artikel wird von der Maschine so verstanden. (Die grafische Darstellung ist hier zu finden.)
Nach mehreren Anläufen (siehe hier und hier) und einem über Jahre gequälten Testblog ist es nun soweit: Dieses Blog ist mit RDFa-Markup angereichert. Mit RDFa kann ich standardisierte, computerlesbare Zusatzinformationen in die Seite einfügen. Leider verhindert twoday.net, daß ich das volle Potential der Technologie ausschöpfe (dazu mehr später), aber zumindest ein paar Basics zur Seitenstruktur konnte ich umsetzen. Eine Suchmaschine erkennt nun besser, was der eigentliche Artikel ist, wo die Kommentare anfangen, ob ein Datum einfach nur zufällig auf der Seite steht oder die Erstellungszeit eines Kommentars bezeichnet und so weiter. Wie das konkret aussieht, zeigt Google. Dieser Artikel wird von der Maschine so verstanden. (Die grafische Darstellung ist hier zu finden.)
Erfahrungen? Grundsätzlich positiv. Ich habe RDFa 1.1 verwendet und bin so den Fallstricken aus dem Weg gegangen, über die man stolpert, wenn man den Server nicht selbst kontrollieren und deshalb kein echtes XHTML ausliefern kann. In einigen Fällen hätte ich mir die elegante Namensraum-Systematik von XHTML und RDFa 1.0 zurück gewünscht, aber das ist wohl nur Geschmackssache.
Ein bißchen übel war, daß ich ständig auf das Vokabular aus schema.org Rücksicht nehmen mußte. Man kann darauf nicht verzichten, weil die großen Suchmaschinen dieses Vokabular bevorzugt verwenden. Andererseits ist schema.org teilweise extrem mühsam und umständlich. Es dupliziert längst vorhandene Funktionen aus anderen Vokabularen, tut dies dann aber nur halbherzig oder kompliziert … Man merkt einfach, daß hier oberflächlich zusammengeschustert wurde, während etablierte Standards wie Dublin Core oder SIOC durch jahrelangen Input aus der Community ausgereift sind. Beispiel: Das Beschreiben von Kommentaren und Antworten auf Kommentare ist in schema.org de facto unmöglich. In SIOC? Ein Kinderspiel. Oder: Das Hervorheben des Autors, wenn man nicht gleich den ganzen Namen verraten, sondern sich auf ein Pseudonym beschränken will (wie hier üblich). Im RDF-Universum leicht über Dublin Core abzuhandeln, mit schema.org ein Eiertanz.
Mein Kompromiß: Ich verwende mehrere Vokabulare parallel. Mag sein, daß Google und Yahoo! keine Informationen aus SIOC, FOAF oder Dublin Core auswerten wollen, aber vielleicht tuts ja jemand anderer. Wo es ging, hab ich auch schema.org verwendet.
Die große Enttäuschung kommt nicht aus RDFa, sondern von unserem twoday.net-Server. Ich kann hier nämlich appetitliches RDFa in die fixen Abschnitte rund um die Blog-Postings und Kommentare herum einbauen. Ich kann RDFa aber nicht im Blog-Posting selbst verwenden. Das reduziert die Nützlichkeit dann doch. Die fixen twoday-Vorlagen wissen ja nichts über den Inhalt des Artikels. Sie wissen, was Überschrift, was Artikel, was Kommentar ist. Sie wissen, wo das Erstellungsdatum steht, in welche Unterkategorie der Artikel gehört, wer ihn geschrieben hat. Diese Informationen kann ich also in RDFa übersetzen. Genau das habe ich getan, genau das kann Google jetzt verwenden. Was nicht geht ist, den Inhalt selbst aufzufetten. RDFa würde mir erlauben, bei Rezepten genau anzugeben: Was ist eine Zutat, welches Foto stellt das fertige Gericht dar, welcher Teil des Textes bezeichnet die Zubereitungszeit, … Oder bei Ereignissen wie meinem Geburtstag oder einem Konzert: Was genau ist es, wo findet es statt, wann beginnts, wie lange dauert es, … Oder auch nur beim Foto neben dem Blog-Artikel anzugeben, wen es abbildet. Nichts davon kann twoday.net. Ich kann den entsprechenden Code beim Erstellen des Artikels zwar eingeben, beim Löschen aber fliegt er raus, weil der Server ihn nicht für gültiges HTML hält. Schade.
Immerhin: der Anfang ist gemacht. Wir sind Semantic Web! :)
RDFa:






{kind=link}